Explaining KZG Commitment with Code Walkthrough
KZG is a popular polynomial commitment scheme widely used in zero knowledge protocols. The core idea is that a prover would be able to commit a polynomial, and later on prove to a verifier the value of the polynomial at a given point. This can be done without revealing the underlying polynomial. The reason that it is so useful is that for anything that can be encoded into a polynomial, can now be easily selective disclosed. For example, we can encode a membership set as points on the polynomial, and using KZG, we can easily generate proof of membership or proof of non-membership. Another example is that we can encode circuit constraints in zero knowledge proofs as a polynomial, and verifier could ask for random points to ensure that the constraints are met.

KZG is so widely used that there are already many open source libraries, such as an implementation provided by Arkworks. However, I couldn’t find a basic implementation that goes through KZG step-by-step with explanations, and decided that writing my own barebone implementation coupled with this article could be helpful for those looking to fully understand the KZG commitment scheme.
The first step of KZG is to perform a trusted setup to generate a common reference string. Essentially, it’s a multi party computation (MPC) to generate a secret such that as long as one party is honest, we can guarantee the randomness of the secret. For KZG, the common reference string is an array where each element is group element G1 multiplied by the secret to the power of i, and i is from 0 up to the degree of the polynomial. Background reading on group element can be found here!
Next, we commit the polynomial by multiplying the coefficients of the polynomial with the common reference string. The size of the commitment is just a group element of an elliptic curve group. For example, for the BLS12_381 curve, this is merely 48 bytes.
Now, when the prover would like to provide a proof that a particular point on the polynomial evaluate to a value, say point f(a) = y, the prover will provide the proof in the form of a quotient.

The intuition behind the proof is that at point a, the polynomial evaluate to y. If we move the polynomial down by y (i.e. f(x) — y), the resulting polynomial has a root at point a, meaning it can be divided by (x-a). Therefore, f(x) — y / x — a gives rise to a quotient.

To verify the proof, the verifier will compute the bilinear pairing. A higher level explanation of bilinear pairing is to take two different group elements of an elliptic curve and map them to a third group element (I like to think of it as enabling multiplication on an elliptic curve). Looking at the equation below, we can see that the left hand side is a pairing between the proof (which is in group element G1), and the difference between the secret and point to be evaluated (in group element G2). The right hand side is the difference between the polynomial and the evaluated point (in group element G1), paired with the group element G2. Essentially, it is to verify that q(s) * (s-a) is equal to f(s) — y, which is the same equation that we used to generate the proof, except we substitute the unknown variable x with the secret generated through the trusted setup, s.
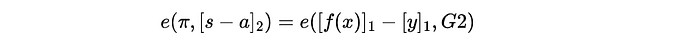
That’s the overview of the KZG polynomial commitment scheme. The workflow consists of four phases: i) trusted setup, ii) committing a polynomial, iii) opening a point and iv) verification. The full code of the KZG implementation can be found here.
This is a more practical walkthrough than fully explaining all the maths behind KZG. Dankrad provided a very good explanation on how KZG actually works under the hood, a recommended read! Let me know if any feedback or questions!